本文引入主題的概念,利用聚合式階層分群法(HAC) 將字面相近的詞彙歸入同一個主題,視為網路中的一個節點。將所有的主題節點構成全聯接圖,而邊的權重則是兩個主題中任兩詞的距離差的倒數之總和,接下來即利用 PageRank 計算每個主題節點的重要度。最後按照經驗法則,選出每個主題中的代表辭彙。此方法使用四個資料集進行實驗,於其中三個表現良好。
ACL 2013
https://www.aclweb.org/anthology/I13-1062/
此文章旨在使用主題而非詞彙為排序的最小單位,其好處有二:其一為能夠較好的涵蓋所有牽涉到的主題;其二為使用全聯接圖能夠更好的捕捉主題之間的關係。
如何組成主題?把所有候選詞分群,這邊使用的是聚合式階層分群法(HAC),連接的策略用 average linkage,相似度量用詞袋向量的相似度,分群的切割點在於相似度大於 75%。
網路圖由主題節點構成全聯接圖,每條邊的權重是兩個主題中任兩詞的距離差的倒數之總和。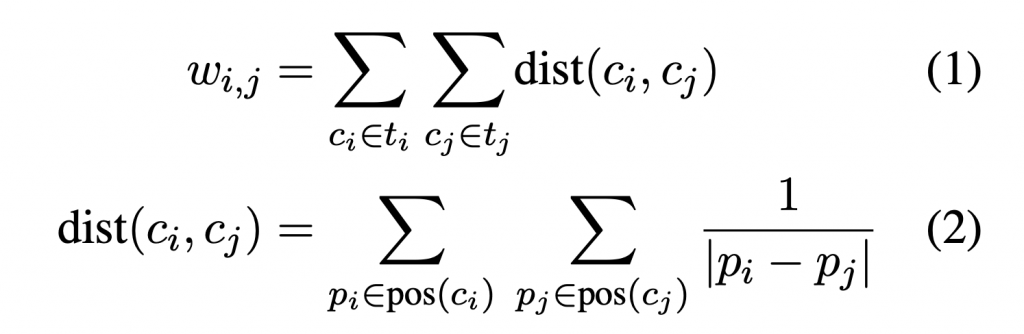
將圖建構完成之後,就可以運行經典的PageRank演算法。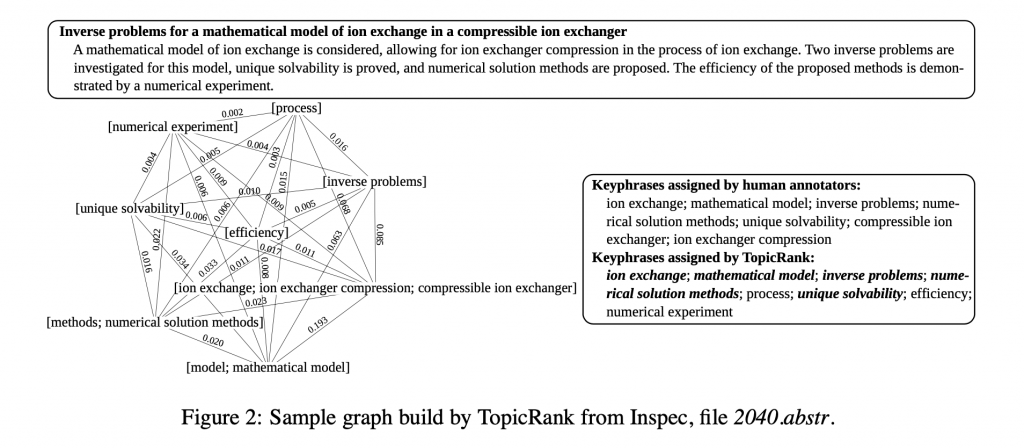
根據PageRank分數,選出前 k 個主題節點。
從主題中選出代表的詞彙作為候選詞,此文嘗試的方法有三種:
資料集的部分,此文使用了四種不同資料集,分別是 Inspec、SemEval、WikiNews、DEFT,種類分別是摘要、論文、新聞、論文,其中後二者是法文。
第一個實驗比較的演算法有三種,分別是 TDIDF、TextRank 和 SingleRank。可以看到,在長文章時,表現得都較過去的演算法強,但在短文資料集 Inspec 則表現較差。(我猜可能是短文章比較沒有需要聚合的對象?)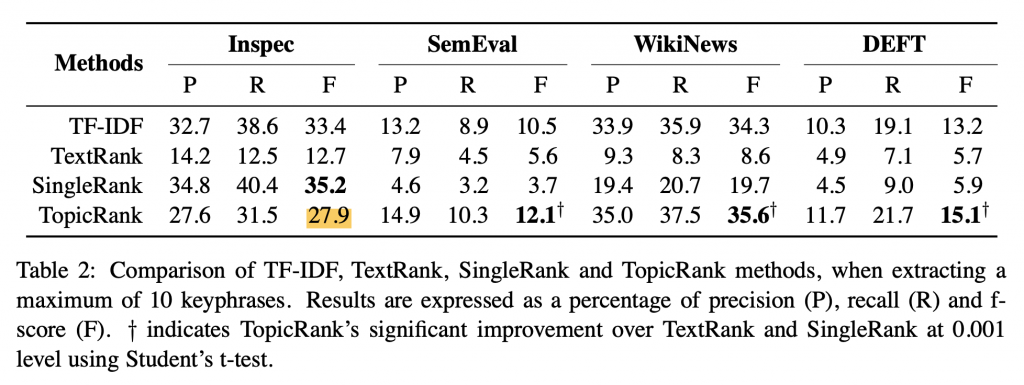
第二個個實驗觀察就現有的 SingleRank 加上 TopicRank 裡面用到的三個改進技巧,能夠提升多少表現。改進的部分分別是,以詞(而非字)為節點,以主題為節點,最後是用字來建構以位置差為邊權重的全聯接圖。這個實驗比較看不出個改進方法的效益。可觀察到的比較有趣的有兩個現象:
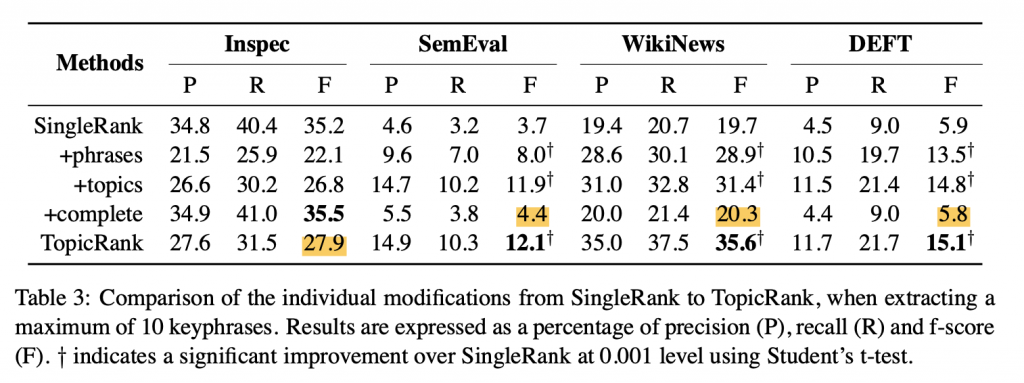
第三個實驗是測試不同的挑選主題代表詞的策略,令人意外的是,centroid 策略表現竟然如此之差。這代表主題中的詞彙其實各個是很不相近的?才會讓橋樑式的詞彙(比方說虛詞)成為 centroid?